H2DBにはLinked Tablesという機能があります。外部テーブル(ほかのDB)へのテーブルリンクを作成して、あたかも H2DB 内に存在するテーブルかのように扱う機能です。
JDBCドライバで接続できるDBであれば、以下のようなコマンドで利用可能です。
CREATE LINKED TABLE LINK('org.h2.Driver', 'jdbc:h2:./test2', 'sa', 'sa', 'TEST');社内に MySQL や PostgreSQL などいろんなDBサーバが乱立しているようなときに使ったら便利そう、ということで調べてみることにしました。
環境構築
docker-composeを使ってお試し環境を作ってみました。h2db + mysql + postgresql な環境です。githubに一式を公開してあります。
https://github.com/komina77/h2db
git clone https://github.com/komina77/h2db.git
cd LinkedTables
docker-compose up -dサンプルデータは MySQL の公式サイトにあるサンプルデータ(world)を利用させてもらうことにします。これを mysql と postgresql の両方の初期データとしてインストールすることにします。(postgresql へはそのままの文法では食わせることはできなかったので少し書き換えています)
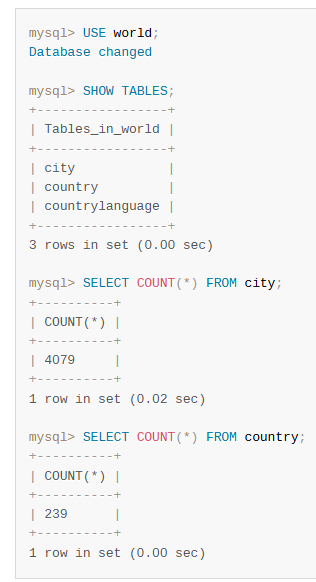
city, country, countryLanguage の3つのテーブルから構成されるデータベースになります。
MySQLを参照してみる
実はH2DBのサーバに内蔵されているWeb管理画面はH2DB以外のDBにも接続できますので、これを利用してみたいと思います。
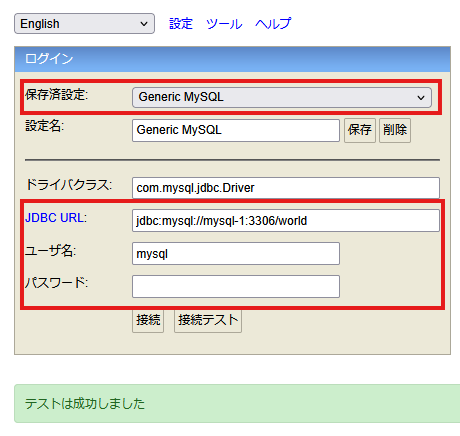
ホストOS上のブラウザで、http://localhost:8082/ を開き、保存済設定の中から「Generic MySQL」を選びます。ドライバクラスなどのデフォルト設定が表示されるので、JDBC URLやユーザ名、パスワード(mysql/mysql)を入力します。接続テストが通れば成功です。
PostgreSQLを参照してみる
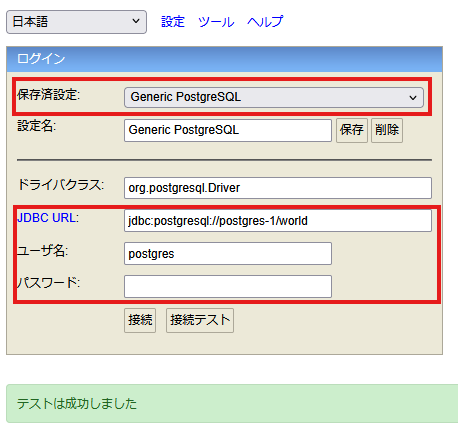
同様に PostgreSQL のデータベースも参照することができます。
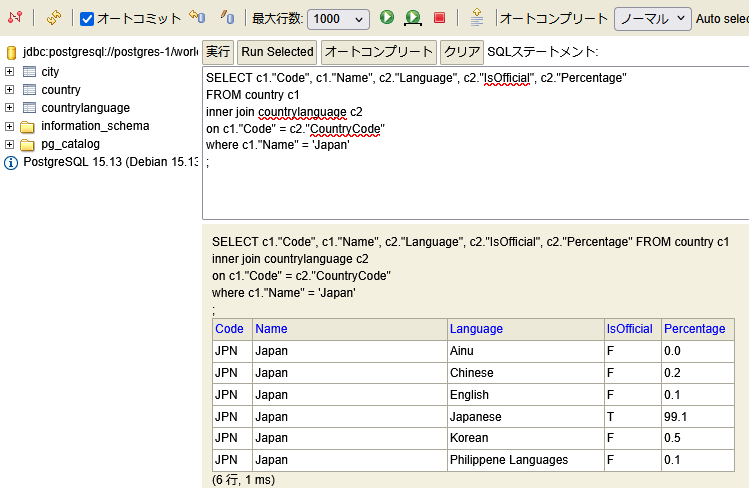
オートコンプリート機能も有効で、ちょっとしたSQLならすぐに試してみることができます。PostgreSQLの大文字小文字混在のカラムはダブルコーテーションで囲わないといけないので、逆に不便でした。
Linked Tables を定義してみる
mysql と postgresql の準備ができたところで H2DB に接続して Linked Tables を作成してみたいと思います。
まずは mysql の worldデータベースの中の countryテーブルを my_country という名前で参照できるようにしてみます。
CREATE LINKED TABLE IF NOT EXISTS MY_COUNTRY(
'com.mysql.jdbc.Driver', 'jdbc:mysql://mysql-1:3306/world', 'mysql', 'mysql', 'country'
);これだけで MY_COUNTRY というテーブルをローカルにあるテーブルのように参照できるようになります。
同様に、PG_CITY と PG_COUNTRYLANGUAGE についてもテーブルを定義します。
CREATE LINKED TABLE IF NOT EXISTS PG_CITY(
'org.postgresql.Driver', 'jdbc:postgresql://postgres-1/world', 'postgres', 'postgres', 'city'
);
CREATE LINKED TABLE IF NOT EXISTS PG_COUNTRYLAUNGUAGE(
'org.postgresql.Driver', 'jdbc:postgresql://postgres-1/world', 'postgres', 'postgres', 'countrylanguage'
);どんなSQLが発行されているか(MySQL
まずは条件なしで検索。
SELECT * FROM MY_COUNTRY SELECT * FROM country T次は簡単な条件を付けてみます。
SELECT * FROM MY_COUNTRY where CODE ='JPN'SELECT * FROM country T
WHERE CODE>='JPN' AND CODE<='JPN'単純な文字列の等号による一致条件のつもりだったのですが不等号の範囲検索に変換されてしまいました。なにか意図があるのでしょうがとりあえずヨシとします。
どんなSQLが発行されているか(PostgreSQL
SELECT * FROM PG_CITY SELECT * FROM public.city TSELECT * FROM PG_CITY
WHERE ID =10SELECT * FROM public.city T
WHERE ID>=$1 AND ID<=$2ERROR: column "id" does not exist at character 35
おっと。エラーが出てしまいました。どうやらDDLの段階でカラム名をダブルコーテーションで囲って大文字小文字を厳密に定義していたことが原因と思われる。。
DDLを修正してもう一度やり直し。PG_CITY と PG_COUNTRYLANGUAGE についてもテーブル定義をやり直します。
SELECT * FROM PG_CITY
WHERE ID =10SELECT * FROM public.city T
WHERE ID>=$1 AND ID<=$2DETAIL: parameters: $1 = '10', $2 = '10'
無事にクエリを発行することができました。
結合したらどうなるか(異DB同士
テーブル一つに対するクエリであれば、ほぼ等価の条件式が渡されるようなので、リンクされた側のDBで適切な実行計画が適用されることになりそうです。
では、2つのDBにまたがる結合をしたらどうなるのか。やってみたいと思います。
SELECT T1.NAME, T2.LANGUAGE FROM MY_COUNTRY T1
INNER JOIN PG_COUNTRYLAUNGUAGE T2
ON T2.COUNTRYCODE = T1.CODE
AND T2.ISOFFICIAL ='T'
WHERE T1.REGION = 'North America'
;北アメリカの国における公用語は?、という感じの意味合いになります。まず MY_COUNTRY を北アメリカで絞り込んだのち、国コードで PG_COUNTRYLANGUAGE から公用語を得る、という結合になることを想定してみました。
MySQL
SELECT * FROM country T WHERE CODE>='ABW' AND CODE<='ABW'
SELECT * FROM country T WHERE CODE>='AFG' AND CODE<='AFG'
SELECT * FROM country T WHERE CODE>='AFG' AND CODE<='AFG'
SELECT * FROM country T WHERE CODE>='AIA' AND CODE<='AIA'
SELECT * FROM country T WHERE CODE>='ALB' AND CODE<='ALB'
SELECT * FROM country T WHERE CODE>='AND' AND CODE<='AND'
SELECT * FROM country T WHERE CODE>='ANT' AND CODE<='ANT'
SELECT * FROM country T WHERE CODE>='ANT' AND CODE<='ANT'
SELECT * FROM country T WHERE CODE>='ARE' AND CODE<='ARE'
SELECT * FROM country T WHERE CODE>='ARG' AND CODE<='ARG'
SELECT * FROM country T WHERE CODE>='ARM' AND CODE<='ARM'
:
:PostgreSQL
SELECT * FROM public.countrylanguage T WHERE ISOFFICIAL>=$1 AND ISOFFICIAL<=$2
-- parameters: $1 = 'T', $2 = 'T'どうやら想定と逆に、PG_COUNTRYLANGUAGE から公用語の一覧を取得したのち、対応する国の一覧を取得。クエリには北アメリカでの絞り込みは入っていないので H2DB側で一番最後に行われたようです。
実行計画を見てみる
事後になりますが H2DBでの実行計画を見てみます。
EXPLAIN
SELECT T1.NAME, T2.LANGUAGE FROM MY_COUNTRY T1
INNER JOIN PG_COUNTRYLAUNGUAGE T2
ON T2.COUNTRYCODE = T1.CODE
AND T2.ISOFFICIAL ='T'
WHERE T1.REGION = 'North America'
;
SELECT
"T1"."NAME",
"T2"."LANGUAGE"
FROM "PUBLIC"."PG_COUNTRYLAUNGUAGE" "T2"
/* PUBLIC."": ISOFFICIAL = 'T' */
/* WHERE T2.ISOFFICIAL = 'T'
*/
INNER JOIN "PUBLIC"."MY_COUNTRY" "T1"
/* PUBLIC."": CODE = T2.COUNTRYCODE */
ON 1=1
WHERE ("T1"."REGION" = 'North America')
AND (("T2"."ISOFFICIAL" = 'T')
AND ("T2"."COUNTRYCODE" = "T1"."CODE"))FROM句で指定していたテーブルが MY_COUNTRY から PG_COUNTRYLANGUAGE に変わっていますね。H2DB では結合順序指定するヒント句はサポートされていません。性能を高めるには希望する結合順になるまで SQLをこねくり回すしかなさそうです。
結合したらどうなるか(同DB同士
同じDBにあるテーブル同士の結合も試してみます。
EXPLAIN
SELECT T1.COUNTRYCODE ,T1.DISTRICT , T1.NAME , T2.LANGUAGE
FROM PG_CITY T1
INNER JOIN PG_COUNTRYLAUNGUAGE T2
ON T2.COUNTRYCODE =T1.COUNTRYCODE
WHERE T1.POPULATION >7000000
AND T2.ISOFFICIAL ='T'
;
SELECT
"T1"."COUNTRYCODE",
"T1"."DISTRICT",
"T1"."NAME",
"T2"."LANGUAGE"
FROM "PUBLIC"."PG_CITY" "T1"
/* PUBLIC."": POPULATION > 7000000 */
/* WHERE T1.POPULATION > 7000000
*/
INNER JOIN "PUBLIC"."PG_COUNTRYLAUNGUAGE" "T2"
/* PUBLIC."": COUNTRYCODE = T1.COUNTRYCODE */
ON 1=1
WHERE ("T2"."COUNTRYCODE" = "T1"."COUNTRYCODE")
AND (("T1"."POPULATION" > 7000000)
AND ("T2"."ISOFFICIAL" = 'T'))人口が700万人超の都市のある国の公用語の一覧を得るクエリです。PostgreSQL へは以下のクエリが送信されました。
SELECT * FROM public.city T WHERE POPULATION>=$1
-- parameters: $1 = '7000000'
SELECT * FROM public.countrylanguage T WHERE COUNTRYCODE>=$1 AND COUNTRYCODE<=$2
-- parameters: $1 = 'BRA', $2 = 'BRA'
SELECT * FROM public.countrylanguage T WHERE COUNTRYCODE>=$1 AND COUNTRYCODE<=$2
-- parameters: $1 = 'GBR', $2 = 'GBR'
SELECT * FROM public.countrylanguage T WHERE COUNTRYCODE>=$1 AND COUNTRYCODE<=$2
-- parameters: $1 = 'IDN', $2 = 'IDN'
SELECT * FROM public.countrylanguage T WHERE COUNTRYCODE>=$1 AND COUNTRYCODE<=$2
-- parameters: $1 = 'IND', $2 = 'IND'
SELECT * FROM public.countrylanguage T WHERE COUNTRYCODE>=$1 AND COUNTRYCODE<=$2
-- parameters: $1 = 'IND', $2 = 'IND'
SELECT * FROM public.countrylanguage T WHERE COUNTRYCODE>=$1 AND COUNTRYCODE<=$2
-- parameters: $1 = 'JPN', $2 = 'JPN'
SELECT * FROM public.countrylanguage T WHERE COUNTRYCODE>=$1 AND COUNTRYCODE<=$2
-- parameters: $1 = 'CHN', $2 = 'CHN'
SELECT * FROM public.countrylanguage T WHERE COUNTRYCODE>=$1 AND COUNTRYCODE<=$2
-- parameters: $1 = 'CHN', $2 = 'CHN'
SELECT * FROM public.countrylanguage T WHERE COUNTRYCODE>=$1 AND COUNTRYCODE<=$2
-- parameters: $1 = 'KOR', $2 = 'KOR'
SELECT * FROM public.countrylanguage T WHERE COUNTRYCODE>=$1 AND COUNTRYCODE<=$2
-- parameters: $1 = 'MEX', $2 = 'MEX'
SELECT * FROM public.countrylanguage T WHERE COUNTRYCODE>=$1 AND COUNTRYCODE<=$2
-- parameters: $1 = 'PAK', $2 = 'PAK'
SELECT * FROM public.countrylanguage T WHERE COUNTRYCODE>=$1 AND COUNTRYCODE<=$2
-- parameters: $1 = 'TUR', $2 = 'TUR'
SELECT * FROM public.countrylanguage T WHERE COUNTRYCODE>=$1 AND COUNTRYCODE<=$2
-- parameters: $1 = 'RUS', $2 = 'RUS'
SELECT * FROM public.countrylanguage T WHERE COUNTRYCODE>=$1 AND COUNTRYCODE<=$2
-- parameters: $1 = 'USA', $2 = 'USA'700万人超の都市の一覧を取得したのち、国コードを使って1国ずつ PG_COUNTRYLANGUAGE を取得していますね。ISOFFICIAL については記載がないので H2DB側で絞り込みを行っているのでしょう。
同じDBにあるテーブルであっても、結合をそのDBに任せず H2DB内で行っていることが分かりました。
まとめ
H2DBには他のDBのテーブルをH2DB内のテーブルのように見せかける機能がある。複数のシステムのDBを透過的に扱うのに便利。- 外部DBのテーブル定義に依存する。カラム名に大文字小文字混在を許すようなテーブルを参照するときは失敗することがあるので、事前に調査してビューなどを介すなど工夫が必要。
- テーブル1つに対するクエリであればテーブルを持つDB上で抽出が行われるので、性能的には問題なさそう。
- リンクテーブル同士での結合はサポートされている。しかし、
H2DBの判断で実行計画が決まってしまうので性能が出ないことがある。 - 結合するリンクテーブルが同じDBのテーブルであっても、結合がリンク先のDBに任されない。H2DBの判断によって行われる。
異なるシステムで使われているDBのテーブルを一時的に参照するような用途では便利かもしれない。しかし、複雑なクエリで問い合わせるときは性能を出すために苦労することになりそうだ。